Merging
The merge step of the deduplication pipeline typically contains the most complexity. The merge operation will depend on your clinical and business context, your downstream application, and how frequently you will unmerge records.
This section will discuss the major decisions you will need to make when designing your patient merge operation. The authors of FHIR are also drafting a FHIR standard merge operation, however the specification has not been finalized.
Linking Patient Records in FHIR
The FHIR Patient has features to represent the link between source and master records.
The Patient.active element is used to indicate the master record for the patient. When there are multiple Patient resources per-patient in the target system, all but the master record should be marked as "inactive."
The Patient.link element is used to connect duplicate patient records via reference.
For each source record
Patient.link.otherreferences the master recordPatient.link.typetakes the value"replaced-by"
For the master record
Patient.link.otherreferences each source recordPatient.link.typetakes the value"replaces"
Example: Linking patient records
interface MergedPatients {
readonly src: Patient;
readonly target: Patient;
}
/**
* Links two patient records indicating one replaces the other.
*
* @param src - The source patient record which is being replaced.
* @param target - The target patient record which will replace the source.
* @returns - Object containing updated source and target patient records with their links.
*/
export function linkPatientRecords(src: Patient, target: Patient): MergedPatients {
const targetCopy = deepClone(target);
const targetLinks = targetCopy.link ?? [];
targetLinks.push({ other: createReference(src), type: 'replaces' });
const srcCopy = deepClone(src);
const srcLinks = srcCopy.link ?? [];
srcLinks.push({ other: createReference(target), type: 'replaced-by' });
return { src: { ...srcCopy, link: srcLinks, active: false }, target: { ...targetCopy, link: targetLinks } };
}
Master Record Structure
For use cases where patient records are merged, you will need to decide which record is considered the master record. The two most common choices are:
- Create a new
Patientresource in the target system to serve as the master record. - Promote one of the source
Patientrecords to be the the master record, using some predetermined rule.
This decision will affect how data updates will be handled, as well as how the unmerge operation will be implemented.
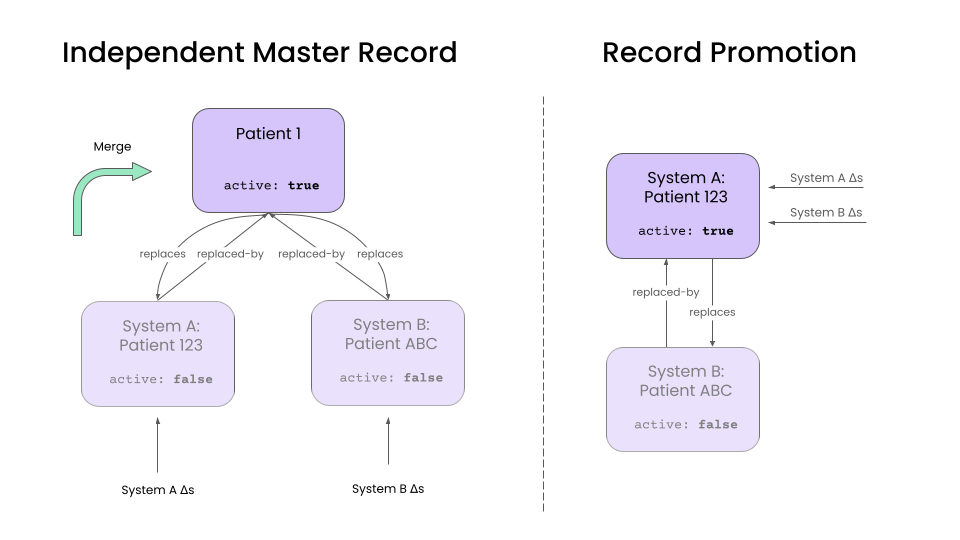
Independent Master Records
This approach creates a new Patient in the target system that represents the merged patient.
Any patient updates in the source system update the corresponding source Patient resource. A separate "merge" operation is then used to combine data from the source records into the master record, and handle any data conflicts.
The advantage of this approach is that it decouples record update and merge operations. It also simplifies the unmerge operation. Because we maintain an up-to-date version of each source record, unmerging simply involves unlinking a source Patient from the master and rerunning the merge operation.
Use this approach if:
- Source systems are long lived.
- Unmerge is an important and frequent operation.
- Duplicates are common.
Example: Merge identifiers of two patient records
/**
* Merges contact information (identifiers) of two patient records, where the source patient record will be marked as
* an old record. The target patient record will be overwritten with the merged data and will be the master record.
*
* @param src - The source patient record.
* @param target - The target patient record.
* @param fields - Optional additional fields to be merged.
* @returns - Object containing the original source and the merged target patient records.
*/
export function mergePatientRecords(src: Patient, target: Patient, fields?: Partial<Patient>): MergedPatients {
const targetCopy = deepClone(target);
const mergedIdentifiers = targetCopy.identifier ?? [];
const srcIdentifiers = src.identifier ?? [];
// Check for conflicts between the source and target records' identifiers
for (const srcIdentifier of srcIdentifiers) {
const targetIdentifier = mergedIdentifiers?.find((identifier) => identifier.system === srcIdentifier.system);
// If the targetRecord has an identifier with the same system, check if source and target agree on the identifier value
if (targetIdentifier) {
if (targetIdentifier.value !== srcIdentifier.value) {
throw new Error(`Mismatched identifier for system ${srcIdentifier.system}`);
}
}
// If this identifier is not present on the target, add it to the merged record and mark it as 'old'
else {
mergedIdentifiers.push({ ...srcIdentifier, use: 'old' } as Identifier);
}
}
targetCopy.identifier = mergedIdentifiers;
const targetMerged = { ...targetCopy, ...fields };
return { src: src, target: targetMerged };
}
Record Promotion
An alternative approach is to promote one of the existing source Patients to being the master record. All updates to the source records are applied directly to the promoted master record.
This is a good approach if your source systems are short lived and if you don't have a high duplication rate, as it reduces the maintenance overhead of an independent master record. The inactive Patient records can be eventually be eliminated as they lose relevance. This is a great pattern in data augmentation use cases, where there is a "primary" source system, and a handful of "supplemental" systems that provide additional data.
However, unmerging is more difficult in this approach, as it requires using the history API to undo updates. Additionally, dealing with data conflicts is more complicated.
With this approach, you'll have to make a few additional design decisions:
- How do you select the promoted record?
- When do you eliminate inactive source records?
Combining and Splitting Master Records
Over time, you may find that two master records actually correspond to the same patient, or that a group of matched records actually correspond to separate patients. This can happen as:
- You accumulate more precise data from your source systems.
- Your matching rules become more advanced.
A key design question will whether your automated pipelines are allowed to combine or split master records after they have been created.
The benefit of automated splitting/merging that your target system always maintains the most accurate master records.
The drawback is that frequently combining and splitting master records can cause instability in downstream systems. This can happen in the early days of pipeline development, when matching and merge rules are still being finalized.
A good middle ground is to have your pipelines flag these cases for human review, rather than combine/split automatically. It is best practice to build a human review process for any patient deduplication pipeline, as no pipeline is free from errors. Integrating combining/splitting decisions into this review process will mitigate downstream instability. The only design question that then remains is when (if ever), the automated pipelines are allowed to override a human reviewer's decision.
Rewriting References from clinical data
After designing a pipeline to handle Patient records, we will have to decide how to deal with clinical data resources, such as Encounters , DiagnosticReports, ClinicalImpressions, etc. The major issue for these records will be how they refer to Patient records.
The two options are:
- Rewrite references to point to the master
Patientrecord. - Maintain references between clinical data and the source
Patientrecords.
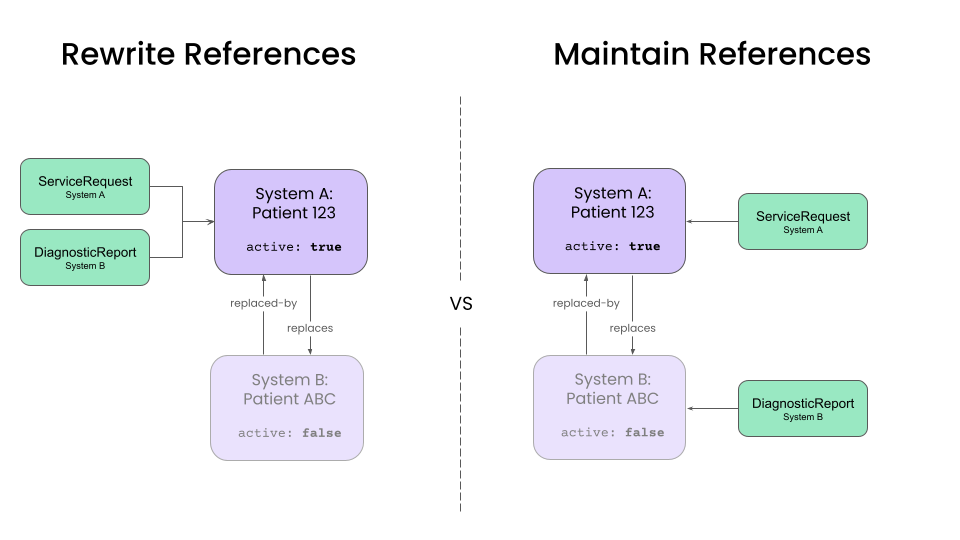
The tradeoff primary will be dictated by the downstream applications and the frequency of unmerge operations.
Rewriting references to master record
Rewriting all references to point to the master record simplifies queries for client applications, and most mature implementations for patient care should target this approach. Web and mobile apps can ignore the existence of source records and simply query for clinical resources associated with the master record. For temporary source systems, this configuration also simplifies the elimination of source records over time.
Example: Update References on Clinical Data
/**
* Rewrites all references to source patient to the target patient, for the given resource type.
*
* @param medplum - The MedplumClient
* @param sourcePatient - Source `Patient` resource. After this operation, no resources of the specified type will refer
* to this `Patient`
* @param targetPatient - Target `Patient` resource. After this operation, no resources of the specified type will refer
* to this `Patient`
* @param resourceType - Resource type to rewrite (e.g. `Encounter`)
*/
export async function updateResourceReferences<T extends ResourceType>(
medplum: MedplumClient,
sourcePatient: Patient,
targetPatient: Patient,
resourceType: T
): Promise<void> {
// Search for clinical resources related to the source patient, by searching for all resources in the patient compartment
// Refer to the FHIR documentation on compartments for more information:
// https://hl7.org/fhir/R4/compartmentdefinition-patient.html
const clinicalResources = await medplum.searchResources(resourceType, {
_compartment: getReferenceString(sourcePatient),
});
for (const clinicalResource of clinicalResources) {
replaceReferences(clinicalResource, getReferenceString(sourcePatient), getReferenceString(targetPatient));
await medplum.updateResource(clinicalResource);
}
}
/**
* Recursive function to search for all references to the source resource, and translate them to the target resource
* @param obj - A FHIR resource or element
* @param srcReference - The reference string referring to the source resource
* @param targetReference - The reference string referring to the target resource
*/
function replaceReferences(obj: any, srcReference: string, targetReference: string): void {
for (const key in obj) {
if (typeof obj[key] === 'object' && obj[key] !== null) {
replaceReferences(obj[key], srcReference, targetReference);
} else if (typeof obj[key] === 'string' && obj[key] === srcReference) {
obj[key] = targetReference;
}
}
}
However, this approach complicates the unmerge operation. Unmerging a single Patient might require rewriting references for a large number of clinical resources. Additionally, we will need to maintain information about the source patient for each clinical resource, which we can do by setting the Resource.meta.source element to a value corresponding to the source system.
Maintaining references to source records
Maintaining references to source records is preferable when absolute clarity about the provenance of each clinical resource is needed. This is preferable in applications such as health information exchanges (HIEs), where data provenance is a higher priority than query performance.
Disabling Merges
In some cases, you may want to completely disable merging for two records. This could be because they are similar, but have been determined not to be duplicates by a human review. In this case you can add them to a Do Not Match List. For more details, see the docs on Do Not Match Lists.
Example: Add record to a Do Not Match List
/**
* Adds a patient to the 'doNotMatch' list for a given patient list.
*
* @param medplum - The Medplum client instance.
* @param subject - Reference to the patient list.
* @param patientAdded - Reference to the patient being added to the 'doNotMatch' list.
*
* @returns - Returns a promise that resolves when the operation is completed.
*/
async function addToDoNotMatchList(
medplum: MedplumClient,
subject: Reference<Patient>,
patientAdded: Reference<Patient>
): Promise<void> {
const list = await medplum.searchOne('List', {
subject: subject.reference,
code: 'http://example.org/listType|doNotMatch',
});
if (list) {
const entries = list.entry ?? [];
entries.push({ item: patientAdded });
await medplum.updateResource({ ...list, entry: entries });
return;
}
console.warn('No doNotMatch list found for patient: ' + subject.reference);
}